上两篇文章讲了怎么把整页的文章下载下来,这一次讲一下怎么把整个专栏的文章都下载下来。讲到这里,一个基础的爬虫基本上都完成了,所以技术方面这些东西并不是有什么神秘的,只是很多东西没有学到,没有思路就会觉得不可思议而已。
在我们开始之前我们先把上次遗留下来的问题解决一下。大家想一下,我们在之前是直接就去循环文章的链接了,尽管我们是根据html文档来进行分析判断的,但是似乎还是不够严谨,因为万一我们的判断失误了呢,那么程序就会没有响应并且一直卡在那里,因此我们应该加一个判断。

因为我们知道find函数在没有找到目标字符的时候返回-1,所以我们应该判断在不返回-1的情况下才对链接进行循环遍历。
开始工作
分析源码
好了,这次我们是要下载整个推理讨论板块的所有文章,我们还是对网站进行分析先。

这是第一页的网址,我们再来看看第二页

再来看看第三页

很好,直觉告诉我们,最后的那个数字应该就是页数的意思了,我们试试改成1看看能不能回到第一页。
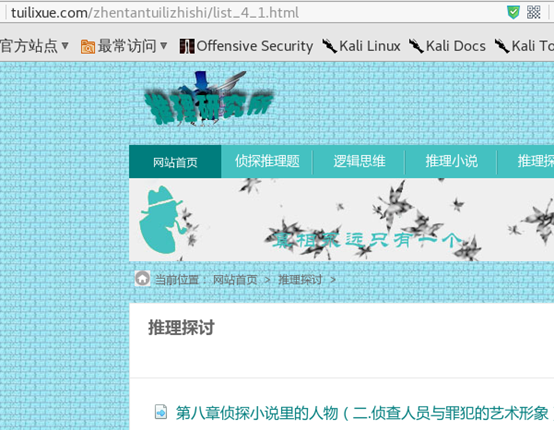
成功的回到了第一页,那么我们来看看需要循环几次
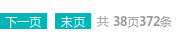
一共有38页,372篇文章,我们先来写一个循环看看能不能正确循环出页数

因为字符串是不能和整型相加的,并且urllib.openg也只能接受字符参数,所以我们这里用str()把页数的数字转换为字符型,并且连接在网址上。测试一下
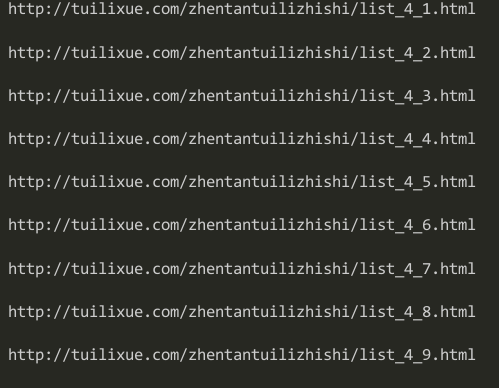
篇幅原因我就不全部截图了,但是我们可以看到,这个循环应该是可以把所有的页数都正确的表示出来的,那么我们现在就要把这个循环语句加到程序中去了。大家想想,我们应该是先到一个具体的页数,然后再爬取该页的链接和文章吧,所以我这个地方的循环应该是加在最外面的一个循环。

这样我们的爬虫基本就完工了,下面我们来做一些其他的事情。
首先是对于网站的压力应对,我们现在写的是一个小爬虫,对网站不能造成什么压力,而且是单线爬虫,如果以后写多线程和爬取的内容多的时候,难免造成对网站的请求过于平凡,很多时候爬虫就会被服务器封杀掉,这时我们就要限制爬虫的速度了。
我们先来导入一个模块
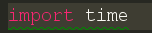
然后在每次下载完成的时候让程序暂停一下,我这里设置的是1秒钟

然后我们再来看看我们的爬虫,大家不知道有没有发现,我们下载的文章的保存名字似乎是一个递增的数字,那么我猜想可能是这个网站累计文章的篇数,为了证实这个猜想,我们到最后几页去看看。我们先来看看37页的html代码.

这是我们发现我们用来命名文件的数字由4位数变成了3位数,又变成了2位数,我们这个时候在来看看我们的下载保存路径。

这时我们要注意到,如果文章命名的数字变成2位数的时候,命名的切片操作会把文章链接中的/符号也加进去,这时就会构成一个新的下载路径了,由于我们并没有这样的路径,所有程序就会报错。具体错误是没有一个这样的文件指向。这个是怎么样的情形大家可以自己去实验一下。下面我们就要解决这个问题,想办法把/替换掉或者去掉。我们当然可以用find找出最后的/的下标,再从下标加1的地方去执行命名,但是这样无疑会多写出几行代码来,而且每次都要去判断,之后命名的代码也要重写,这样似乎工作量就上去了。我们可以换一个想法来解决这个问题,比如说在原有的命名代码中,只要发现有/字符存在的,一律替换为空或者其他。下面我们来看一个函数。
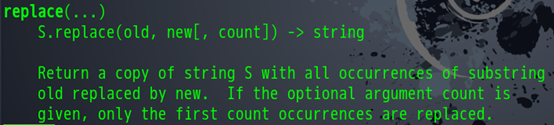
字符串的replace函数可以将字符串中的目标字符替换成其他的字符,这时我们来这样写。

就这样,我们就可以轻松的把我们切片中的/给去掉了我们运行一下看看是否可以下载。先看看目录下面有什么。
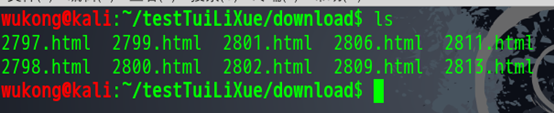
这些都是上一次我们下载的东西,我们删除掉。
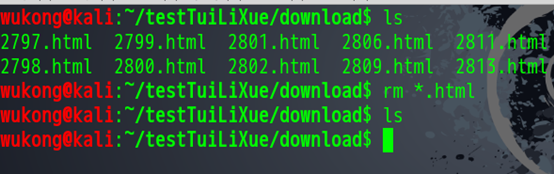
现在目录已经是空的了,我们现在开始下载试试。
一堆end之后我们的文件下载好了,我们去看看.
一大堆的文件,我们看看数量

372个,刚好对应了372篇文章。就这样,我们就完成了一个定制的爬虫。