这篇文章算是我刚刚开始学爬虫的时候写的一个笔记了,现在整理出来,也算是一个分享过程吧。爬虫总体归纳来说就是三个步骤,获取网页源码,定位信息,提取保存信息,我们一个一个来说。
什么是爬虫
我们都用过搜索引擎,嗯,就是Google,百度,必应之类的东西,我们为什么可以在上面搜索出东西来就是因为他们有爬虫程序在后台帮他们收集数据。就像我们要从网上获取数据我们就要去浏览网页,爬虫就是充当了一个浏览网页的机器人,将获取到的信息返回给自己的服务器。
目标
从网页上获取一篇文章
思路
其实我们不必对爬虫感到很神秘,毕竟我们每天都在用的东西。爬虫其实本质上就是在模拟用户的浏览行为,只要我们抓住这一点的话我们就可以围绕这点来展开了。用户浏览网页首先是要打开网页,再从网页上面获取到自己需要的信息,我们可以用爬虫来完成这一行为。
方法
尝试获取到网页的源码,再从中提取数据。
准备工作
因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬疑故事的网站,同时也是因为这个网站在编码上面和一些大网站的博客不同,并不那么规范,所以对于初学者还是有一定的挑战性的。演示系统用的是kali,因为懒得去配置各种py模块了,就利用系统已经配置好的,浏览器是firefox,使用的IDE是微软的vscode。python版本为2.7
查看robots.txt
首先我们选取了我们要爬取的网站http://tuilixue.com/,先检查一下robots.txt看看是否存在有一些反爬虫的信息。
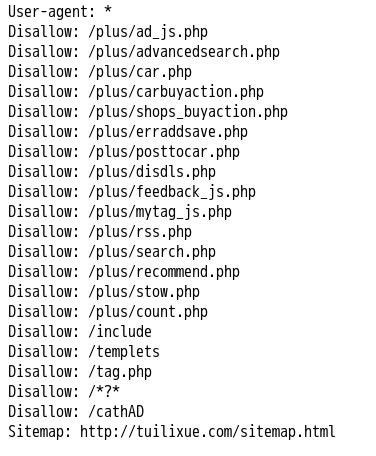
很好,这里没有什么限制
查看目标
然后我们到我平时比较常去的板块看看,http://tuilixue.com/zhentantuilizhishi/list_4_1.html
我们现在想要爬取的文章就是这样的

右击鼠标查看源代码,我们可以看到,我们想要爬取的链接就是这样的

来一张清晰的

开始工作
获取网页源码
但是我们要怎么办才能使python得到这个网页的源代码呢?我们可以使用python的urllib模块提供的open方法,首先我们先新建一个py文件,惯例
因为是linux系统,所以python路径不同于windows,第一行代码说明是用的uft-8进行编码

在这里我们要先导入urllib这个模块,使用import导入。这里其实是两个方法,一个open一个read,open用于从网站上获取网页代码,read是为了读出来好打印。
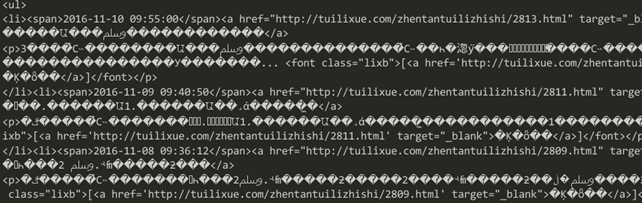
我们可以得到上面结果,但是我们发现字符似乎成了乱码,为了找到原因,我们再来看看源码。

我们似乎找到了原因,网页使用的是gb2312进行编码的,但是我们是使用utf-8的,所以导致的乱码,对这方面不解的同学可以去找一些编码的知识看看。下面我们用一个编码转换来尝试获取正确的编码。
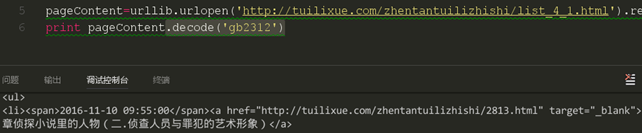
这时可以看到,我们通过强制的编码将获取的网页重新通过gb2312进行编码,我们就可以看到正确的字符了,但是在我们的这次课中并不需要这样的转码,这里只是为了显示获取的是正确的网页,从图中看到,我们获取的正是我们需要进行爬取的页面。
分析源码
下一步,我们需要获取我们本页的所有的文章链接了,这里需要有一点html和css的知识,关于这部分的知识,大家自己去掌握就行了,不需要太深入。如图中显示的,href后面的就是我们在本次课中需要爬取的链接,每页都有10篇文章是我们需要爬取的,我们先从第一篇的链接开始。

这时候我们就要想我们应该怎么样去获取到这个页面的链接了,如果正则表达式好的同学应该是想到了采取正则表达式进行获取,但是这里有一个问题,一个html页面中有如此多的a开头的元素,也有如此多的href开头的元素,想要通过正则去定位还是有点难的,就算定位出来,也是一大堆的代码,这就不利于可读性了。这时我们应该再从html文本中去分析。我们使用type函数进行类型的判断。
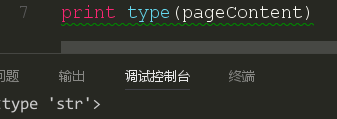
通过对pageContent的类型分析,我们知道这是一个字符串类型,这样我们就可以使用字符串中的find函数了,我们需要对find函数有一个了解。
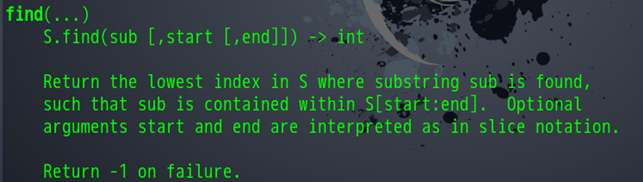
函数中说明了从字符串中寻找目标字符,返回找到的第一个下标,如果没有找到就返回-1,同时可以设置开始寻找的位置和结束的位置。我们再看到文本。

我们发现是在div class=“liszw”下的li元素中的a元素中含有我们需要的链接,这时我们一个个来分析。




这时我们发现这和我们所要爬取的链接数量上是完全吻合的。我们就来试试。
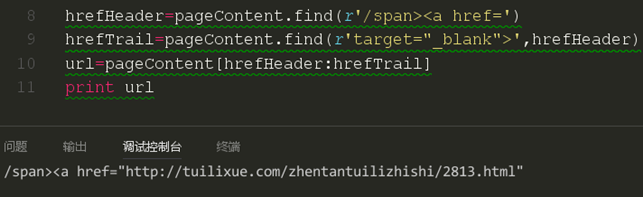
这里我们采取了一个切片操作,这时我们发现链接其实已经爬取到了,但是还是有些不完美,我们再来完善一下他。
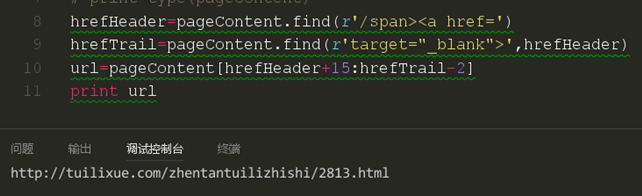
我们来对比一下我们的网页上的第一个链接

保存信息
这样我们就成功的爬取了第一个链接,现在我们来准备下载第一篇文章。从前面我们可以知道,我们可以把网页通过python的urllib模块下载下来,那么同样的道理,我一样也可以通过urllib模块对文章进行下载。我们通过链接的最后一串数字对下载下来的文件进行命名。并在下载玩后打印end进行提示。
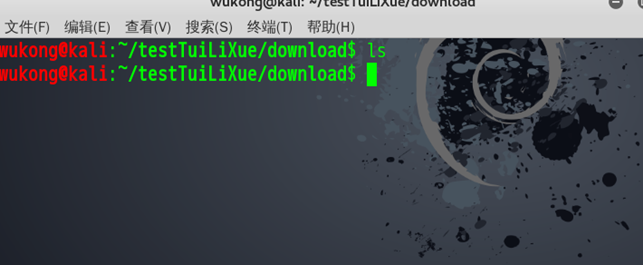
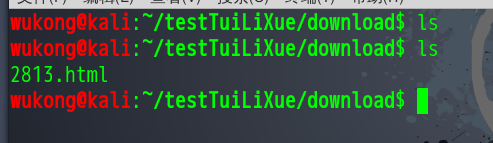
我们可以看到,路径下是没有文件的。现在我们开始下载。
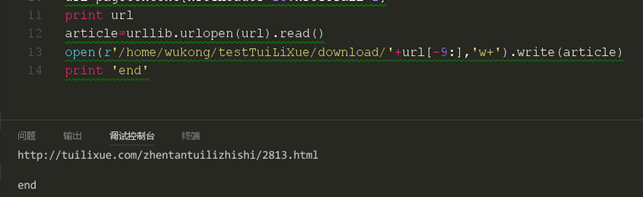
从这里看我们的文件应该是下载成功了,我们去文件路径下面看看。
文件下载是成功了,我们来打开看看。这个地方要注意地址栏的链接
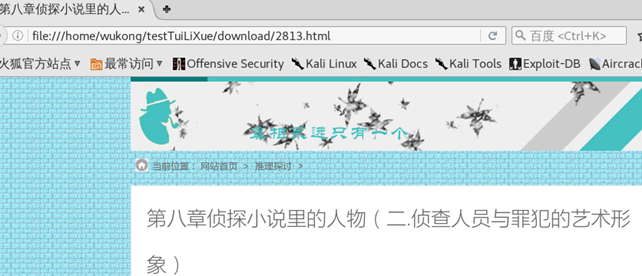
这样,通过三个步骤,我们的爬虫就已经完成了。