有一段时间没有更新博客了,其中原因很多,先是接下了一个公司的工作,当时项目很急,也经常加班,也造成了没有时间去更新博客,后面因为工作中的一些理念不同,我也离开了那个公司到别的地方去工作了,换了新工作很多东西需要去学习和熟悉,换了工作也换了住的地方,这也花费了很多的时间去处理。本来这篇文章在过年的时候就想写的了,结果一晃都半年过去了,现在才动笔。
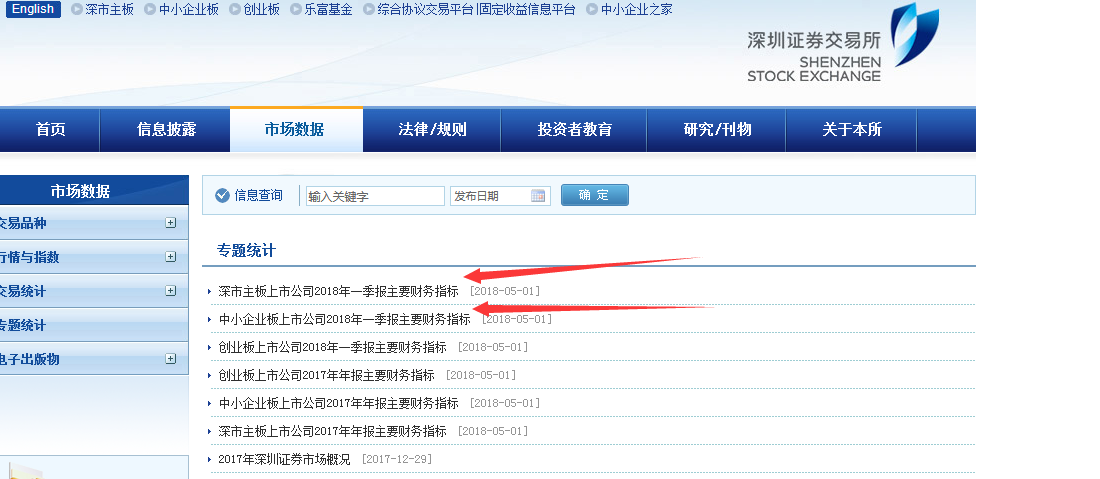
首先还是老规矩,做爬虫,先分析网络请求。其中的目标URL是深圳交易所专题统计,我们要爬取的就是其中的主要财务指标,如图所示.
这样看到这些报告的链接,很多都直接是指向文件的链接,这意味着我们如果直接访问这些链接就相当于是直接访问文件了,如果要保存到本地的话我们只需要用二进制讲访问返回的内容写到本地即可。多翻几页能看出来,文件都是doc,docx,pdf,xlsx,还有shtml之类的组成的,这些不影响,还是采取使用二进制写进到本地进行存储,得到文件之后再进行处理。
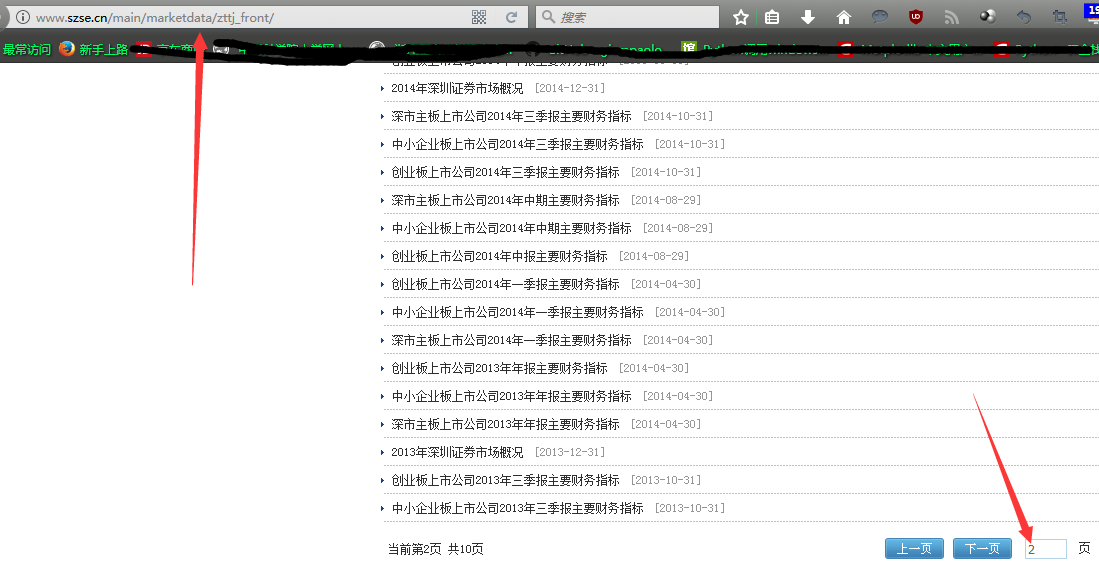
我们再往下看,发现一共有10页,我们尝试点击翻页,看看浏览器上面的链接有没有上面变化。结果我们发现,并没有在url中暴露翻页的信息。
如此这般,那么只只好抓包分析了,上F12,然后点解下一页分析一下请求的情况。
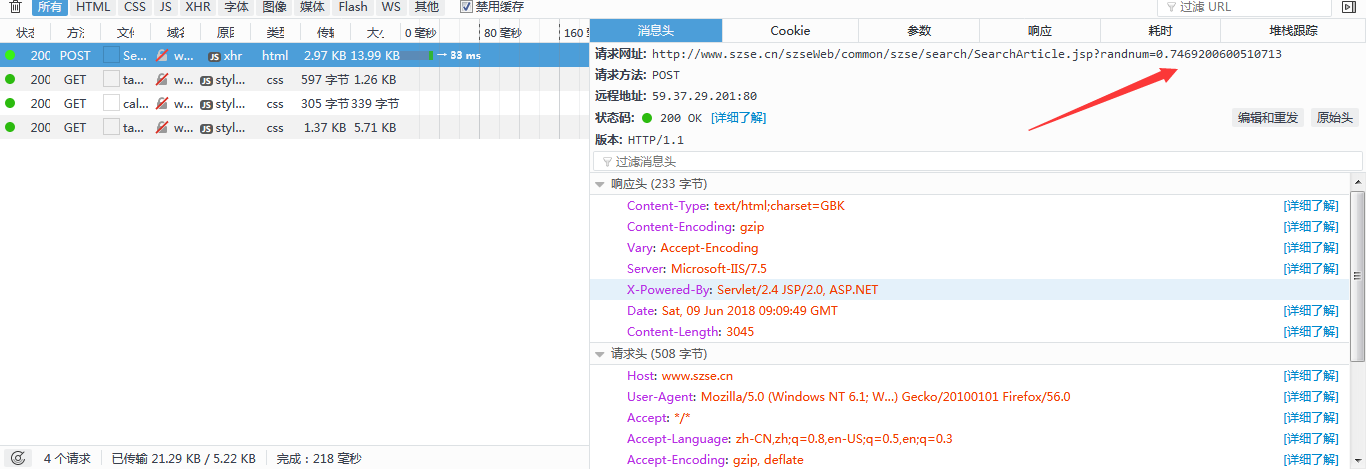
这样看来就很明显了,请求不是很多,不得不说金融行业真是话不多,但是说话都命中要害,减少了很多不必要的开销。看图我们发现是一个post请求,让后返回了一个HTML页面,我们可以看到返回的HTML中有第二页所出现的报告的名字和相应的链接,那么我们也不用去分析别的链接了,就是这个链接了,下面进行分析。
我们可以看到,翻页的时候触发了一个js,再加上一个随机的浮点型数字,我当时翻了一下网页中的代码,奈何金融行业比较社会,人狠话不多,基本没看懂这个随机数是怎么来的,并且每次点击翻页的随机数都不一样,从这个地方看,我基本就放弃使用requests或是urllib来进行访问了。不过爬虫与反爬就是这样子,你有张良计,我有过墙梯,直接使用python发包不行的话就只能借助别的工具来进行访问了。
介绍一个小工具,phantomjs,网上有很多这个工具的教程,重复phantomjs入门使用就不在这里赘述了,关于这个工具,大家可以理解成一个没有界面的浏览器即可。这个小工具下载好了直接双击,然后就会自动在系统里面了,使用的时候只需要将phantomJS和脚本放在一起就行了。
首先,我们先来实例化一个phantomJS无头浏览器。



因为我们第一次打开目标URL的时候其实时用的get请求,于是我们也可以尝试使用phantomJS来进行get请求。
我们发现,在这段代码中可以获取正确的HTML,于是我们再尝试定位到下一页的按钮,尝试是否可以正常点击下一页。
运行之后发现,在phantomJS的click()执行之后,确实是可以获取第二页的HTML,那么翻页暂时来说不是问题了,下面的问题就是怎么把每一页的链接获取到,然后下载文件到本地。我们在网页上点击文件的链接,发现可以直接打开一些文件,这时我们就可以在获取文件链接之后使用python进行请求发包了。来看看下面这段代码。
这样的话文件是下载下来的,但是也仅仅是下载下来了,里面的信息没有办法提取出来,关于这几种文件在python中怎么解析,相关的模块的文档也有,这里也不去介绍入门了。这里有一点需要注意的是,因为doc的兼容性问题,我们可以将其转换成docx再来进行读取,这个地方需要电脑安装了MS office或是wps,因为是调用这两个应用程序的组件进行转换的,此处需要声明一下。多的不说的,代码的注释还是比较详细的,我直接讲代码放出。
整个脚本的代码如下
最后实现的效果是可以进行增量爬取,因为已经爬取过的都会被记录下来,然后在获取到相同链接的时候忽略掉该链接的下载和解析,并且将文件都解析成字符串,如何分析,此处便是后话了。下图是当时爬取的一些记录。