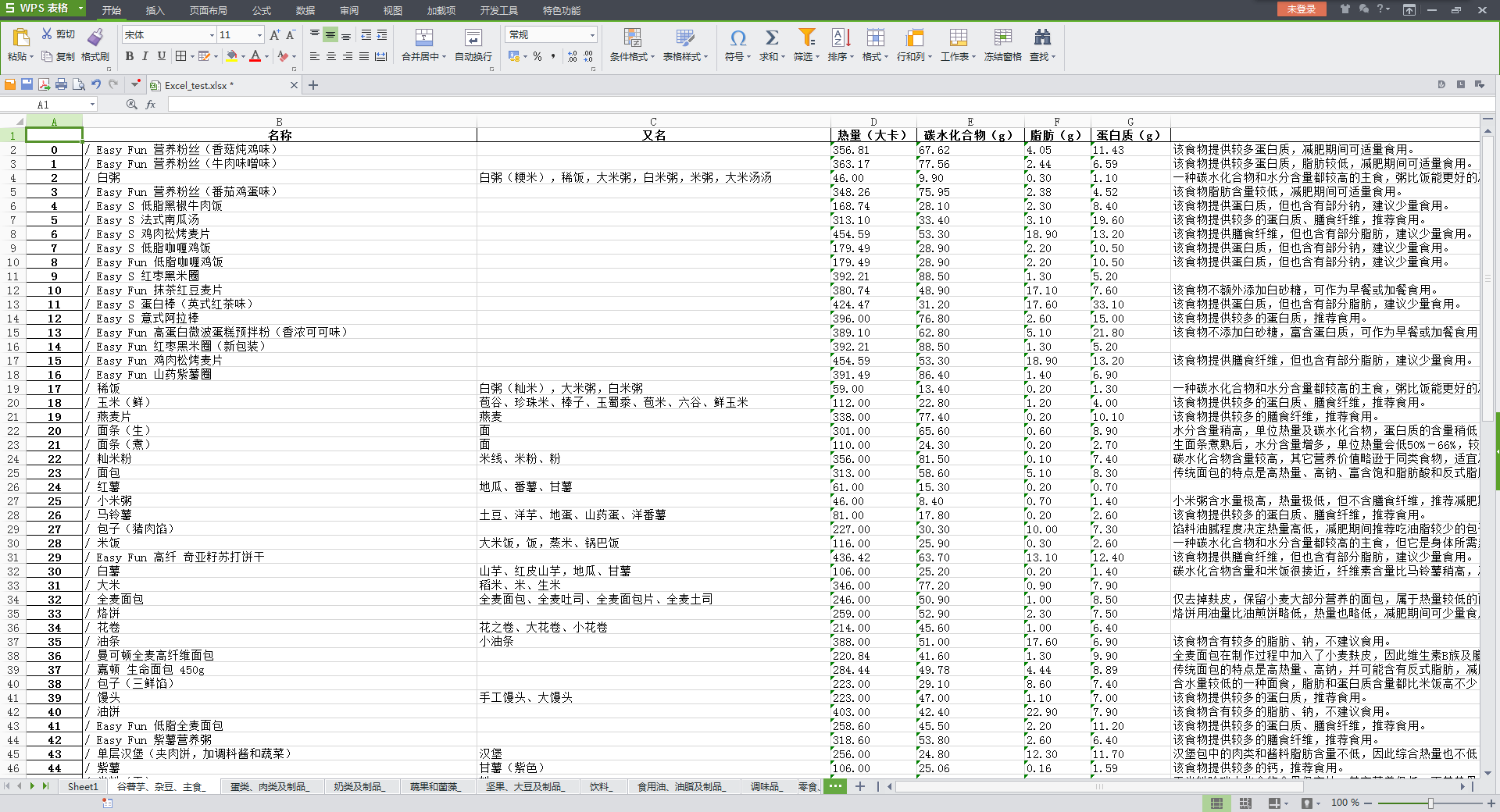
最近想要减肥,想着先从食物入手,在网上查了一下,发现有一个叫薄荷的网站还是不错的,食物都做了详细的分类,并且所有的营养都做了数据的量化,作为制定饮食计划的参考还是不错的。打算先大致的看一下常见的食物营养做到心中有数,再来制定计划。我同时还发现了网上有一篇文章,已经有人爬过薄荷了,但是只是在列表也爬取了热量数据,并没有进到详情页去爬取其他的营养参数。
我们先进到薄荷的食物页面,发现网站将所收录的食物分成了11个大类,我想是将每一个大类放进一个excel表格的sheet里,那么这样的话就有11个sheet了。
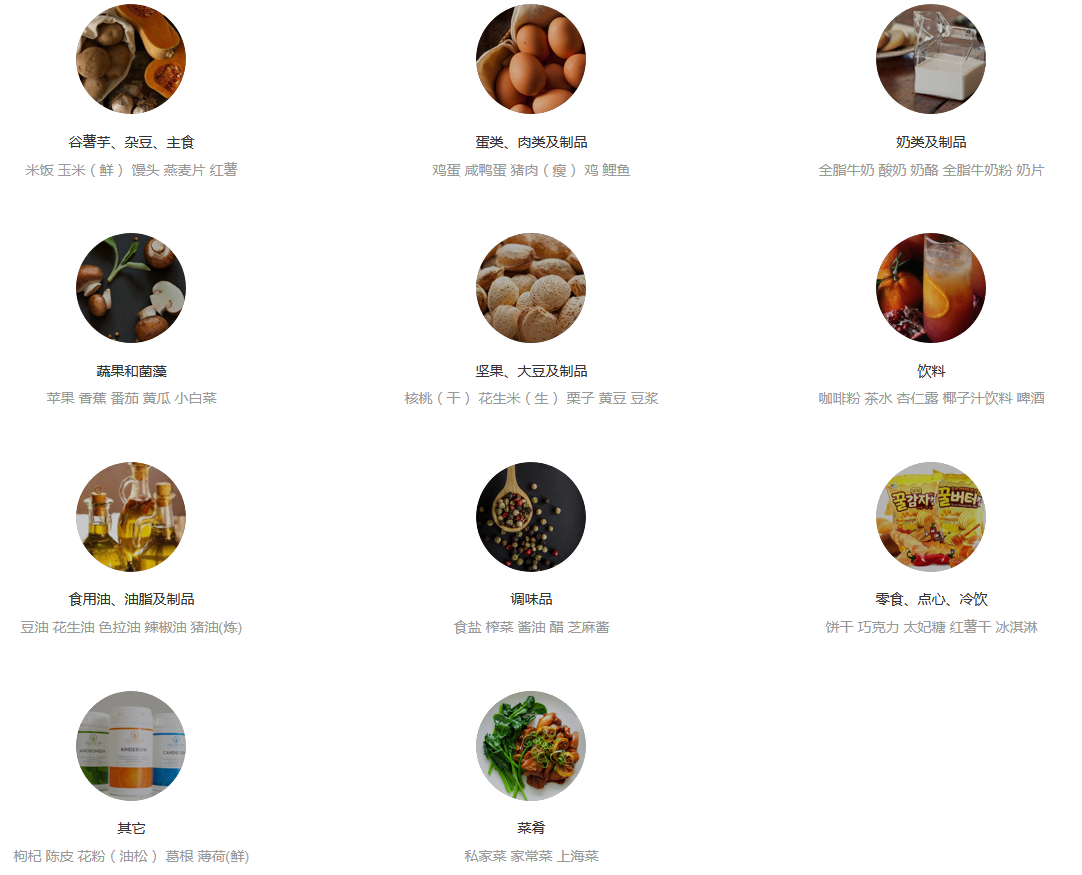
再来看到每一个分类的链接,发现用了短链,在短链的前面应该加上网站的域名’www.boohee.com’,那么先把分类页面爬取下来即可。
导包侠,先预测大概需要那些包
|
|
因为设计是爬取了一个大类就写一次sheet,所以这里使用了yield,每爬取一次处理一次,剩下的后续等待。
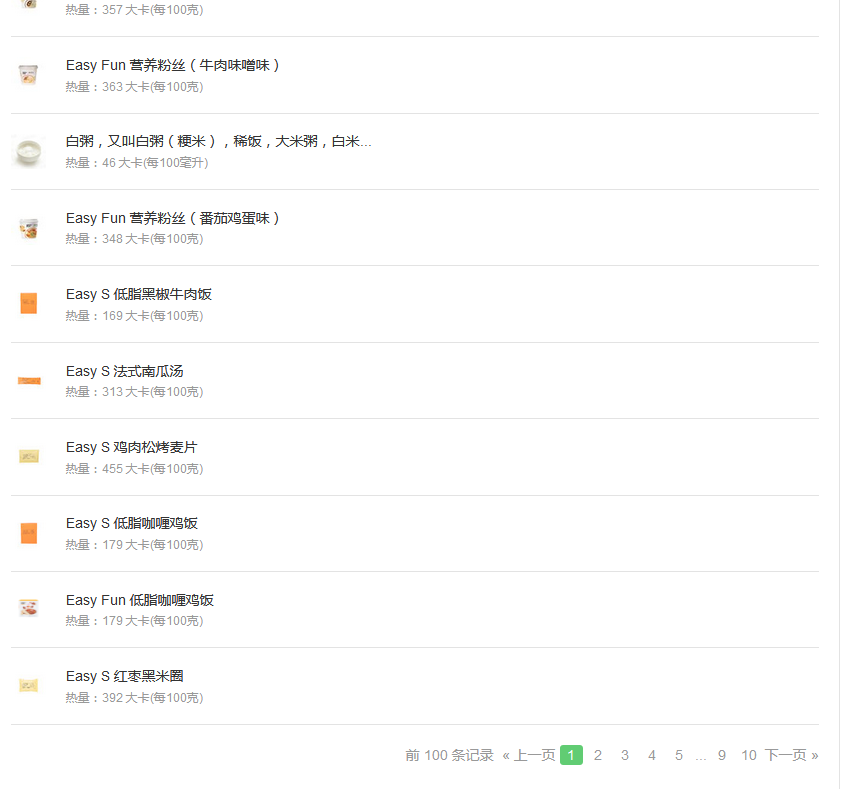
进到分类里面之后就是该分类下面的食物列表了,我发现每一类下面食物大概都有10页的,一页有10种食物,那先把所有的翻页链接拿下。
|
|
在具体的一页中获取该页的所有食物链接,并进入每个链接中获取食物的所有信息。
|
|
上一段代码中的get_detil就是具体在详情页面中定位各种营养数据的实现过程
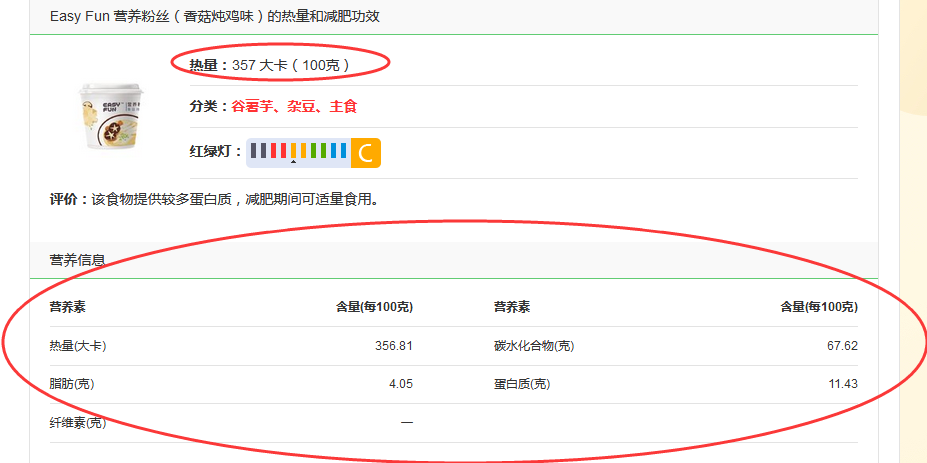
|
|
上面的get_detil的对名字做处理是后面运行的时候才加的,主要是发现了有一些食物在列表页面是有名字的,但是到了详情页面中的时候,名字字段就缺失了,这种情况下xpath的定位就会发生异常,所以我们这里就这样处理先。一开始想在列表也上用名字的,但是这样将会耗费大量的时间在请求上,所以用详情页中的面包屑导航中的信息,但有些面包屑会缺失掉一点。
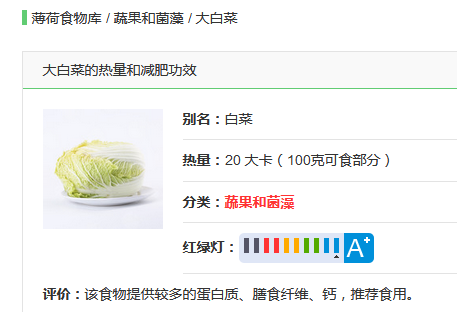
这是正常的面包屑
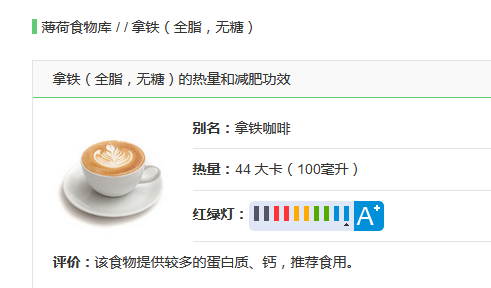
这是异常的面包屑,缺失了分类信息
爬取到的信息要保存,因为信息不是很多,而且我这台电脑上没有安装数据库,所以我就用excel进行保存了。不同的分类保存在不同的sheet里,一开始想直接用pandas模块的excel写入方法的,后面发现不行,找了挺多资料,也做了很多的尝试,发现用openpyxl模块可以实现。
|
|
后面就是把具体的实现步骤连接起来了。
|
|
整个爬虫下来其实没有什么值得说的,如果是单线程的话耗时真的是太久,分析一下,这个爬虫其实最耗时应该是在获取详情的地方,写入excel的数据量并不是太大,所以针对请求做了多线程处理。一开始只是加了一处,发现处理起来快很多,后面在将爬取数据处理成dataFrame中也加入了多线程,整个爬虫的速度确实有变快。
这个爬虫不是太难,就简单的做一个练手的记录吧。